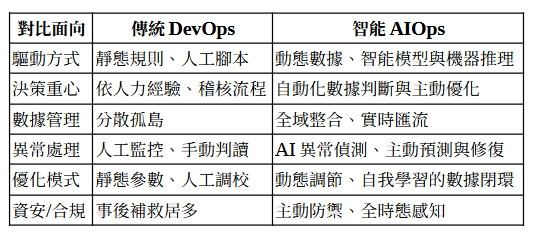
在數位經濟浪潮下,企業因應產品快速創新、用戶動態變化及複雜的系統架構,IT運維從單一技術職能,轉變為數據與智能驅動的“數位戰略核心”。過去十餘年,DevOps從“開發(Development)”與“運維(Operations)”間的壁壘突破,率先實現自動化部署、持續集成(CI)/持續交付(CD),改變了軟體開發的全流程。然而,當企業步入雲原生與多端融合時代,系統規模及事件複雜度飆升,DevOps傳統模式逐漸暴露瓶頸。
**AIOps(人工智慧IT運維)**於焉誕生——它的本質,是以人工智慧(AI)、機器學習(ML)、自動化推理為核心,徹底重構IT運維流程,將運維自“規則驅動”邁向“數據驅動”與“智能判斷”階段。本章旨在全面解析DevOps到AIOps的範式轉移演進、技術路徑與底層邏輯,協助專業人士掌握IT運維升級的關鍵。
DevOps核心原則
DevOps強調將開發與運維團隊緊密協作,推動自動化部署、持續測試與自動化監控。其實踐工具如Jenkins、GitLab CI、Ansible等,讓發佈上線、環境建置、監控告警流程得以自動編排。
優勢歸納
• 效率提升:大幅縮短交付與上線週期,促進產品快速迭代。
• 錯誤降低:流程標準化降低人為疏失。
• 協作優化:消除開發與運維間資訊鴻溝,促成Dev、Ops、QA一體共作。
困境解析
隨著企業應用場景與微服務架構不斷膨脹,DevOps自動化面臨以下痛點:
• 規則僵化:所有自動化流程依賴人為預設規則,針對未知型異常、0-day攻擊等無法實時應變。
• 數據孤島:監控資料分散於各系統,難以跨域匯聚與事件關聯,告警繁雜,易導致警報疲勞。
• 需人力介入決策:異常狀況發生仍需人工判讀、聯絡協調,處理時效大打折扣。
• 自動化擴展受限:對於多雲、混合雲、邊緣計算場景,傳統腳本與自動化工具難以覆蓋全局。
AIOps突破傳統DevOps自動化限制,透過數據匯流、語意分析和自學習模型,打造端到端的智能運維體系。它將IT監控、異常偵測、根因分析、風險預測與主動修復等,徹底納入自動閉環管理,實現多維數據驅動的決策場域。
核心特點
• 數據匯流整合
全網監控、日誌、APM、用戶體驗、IoT設備等多源數據,進行格式統一、時序整理與實時同步,打破資料孤島。
• 智能判斷與預測
利用機器學習、深度學習,從大規模歷史數據中自動學習“常態”與“異態”,持續優化異常檢測的精準度與即時性。
• 自動根因定位與主動修復
告警事件經關聯推理後,系統可自動定位問題根因與影響範疇,並觸發自動修復機制或發送優先級建議,縮短修復週期(MTTR)。
• 持續學習與閉環優化
系統根據過往處理決策、專家標註結果,持續修正模型與優化運維對策,形成AI自我成長的動態閉環。
AIOps不只是DevOps的工具疊加,更是一種運維價值觀的重塑。它要求組織從底層數據治理、流程智能自動化,到組織文化與人才轉型,進行全面升級。
(一)資料匯流與治理
打造全面且規範的資料湖系統,集中納管監控、日誌、配置、績效等多維資料。
(二)大數據處理與即時分析
應用分散式數據流平台(如Kafka、Spark Streaming),支持PB級大數據的高效處理,保證數據時效與準確率。
(三)機器學習/深度學習引擎
• 異常偵測:自動從時序資料中識別異常行為(如Isolation Forest、LSTM等)。
• 根因推理:用關聯圖譜、事件序列建模解析多變量設備間的因果關係。
• 預測維護:預測資源瓶頸、主機失效、流量高峰等。
(四)自動化與智能決策引擎
採用SOAR(Security Orchestration, Automation and Response)、ChatOps協作等方案,讓事件自動派發、自助修復流程閉環。
(五)持續回饋與自主優化
建立人工與AI互動的回饋記錄,驅動機器學習模型不斷進步,提升決策準確度和適應性。
推動AIOps不只是技術工程,更是組織結構與人力資源的躍遷。企業需同步調整運維團隊角色定位、培養數據分析/AI建模專才,升級“流程制定者”為“數據治理+智能監督者”。
本範例模擬AIOps平台中,如何以Python進行多維監控數據的異常分析,並實現自動化處理決策的基本流程。
python
import pandas as pd
from sklearn.ensemble import IsolationForest
# 假設有多種運維指標,如CPU、記憶體與網路流量各自為一欄
df = pd.read_csv('metrics_logs.csv')
# 可根據實際需求抽取多個特徵共同判斷
features = ['cpu_usage', 'memory_usage', 'network_traffic']
X = df[features]
# 建立IsolationForest模型
clf = IsolationForest(contamination=0.02, random_state=2025)
df['pred_anomaly'] = clf.fit_predict(X)
# 找出異常樣本
anomaly_records = df[df['pred_anomaly'] == -1]
print("異常事件明細:")
print(anomaly_records[['timestamp'] + features])
# 基礎自動化回應策略(如:發起自動修復腳本或通知工程師)
if not anomaly_records.empty:
print("發現異常,啟動自動修復流程...")
# 可用自定義函數trigger_auto_remediation(anomaly_records)
else:
print("系統運作正常。")
```
> 說明:
本程式依據多維度監控資料(如CPU、記憶體、網絡)運用Isolation Forest進行異常判斷,不僅可大幅減少人力巡檢的負荷,還可作為後續自動化流程(如自動修復、通知等)的決策依據,體現AIOps從數據驅動、智能判斷到流程自動化的閉環。
## 結語
DevOps與AIOps的核心差異,不僅僅在技術堆疊,更在於運維哲學的轉型——從規則導向、人工決策,升級為數據整合、AI驅動、系統自進化。AIOps為現代IT運維注入智能自動化基因,讓企業能真正以數據為基礎,實現主動防禦、高韌性、低人力的智能運營新時代。隨著底層數據治理與智能模型不斷進化,未來AIOps將成為企業競爭力新引擎,共創自動到智慧的新價值。

